Recently, a software development outsourcing agency introduced a new kind of timed behavioral test — one that might secretly be assessing a candidate's ability to effectively leverage GenAI skills. This test requires solving complex math, reasoning, and logic problems within an extremely short time frame.
Although no instructions were given regarding the use of GenAI prompting, I personally believe this is, in reality, a test of your GPT skills. The sheer volume and complexity of the questions make it unlikely that someone could complete the entire test without AI assistance.
Ultimately, this test evaluates more than just problem-solving — it gauges your ability to select the right AI model for each challenge and demonstrate proficiency in advanced prompt engineering.
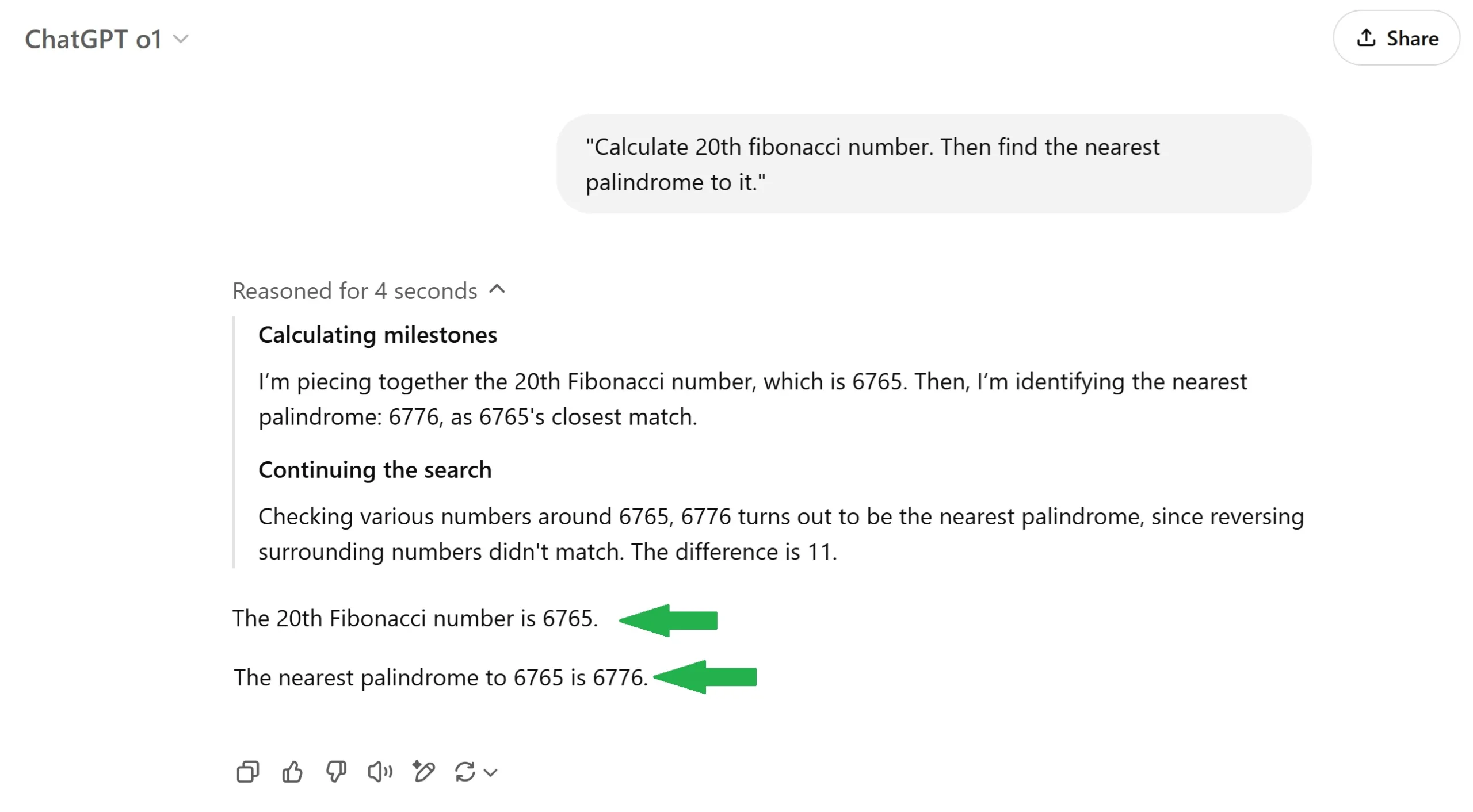
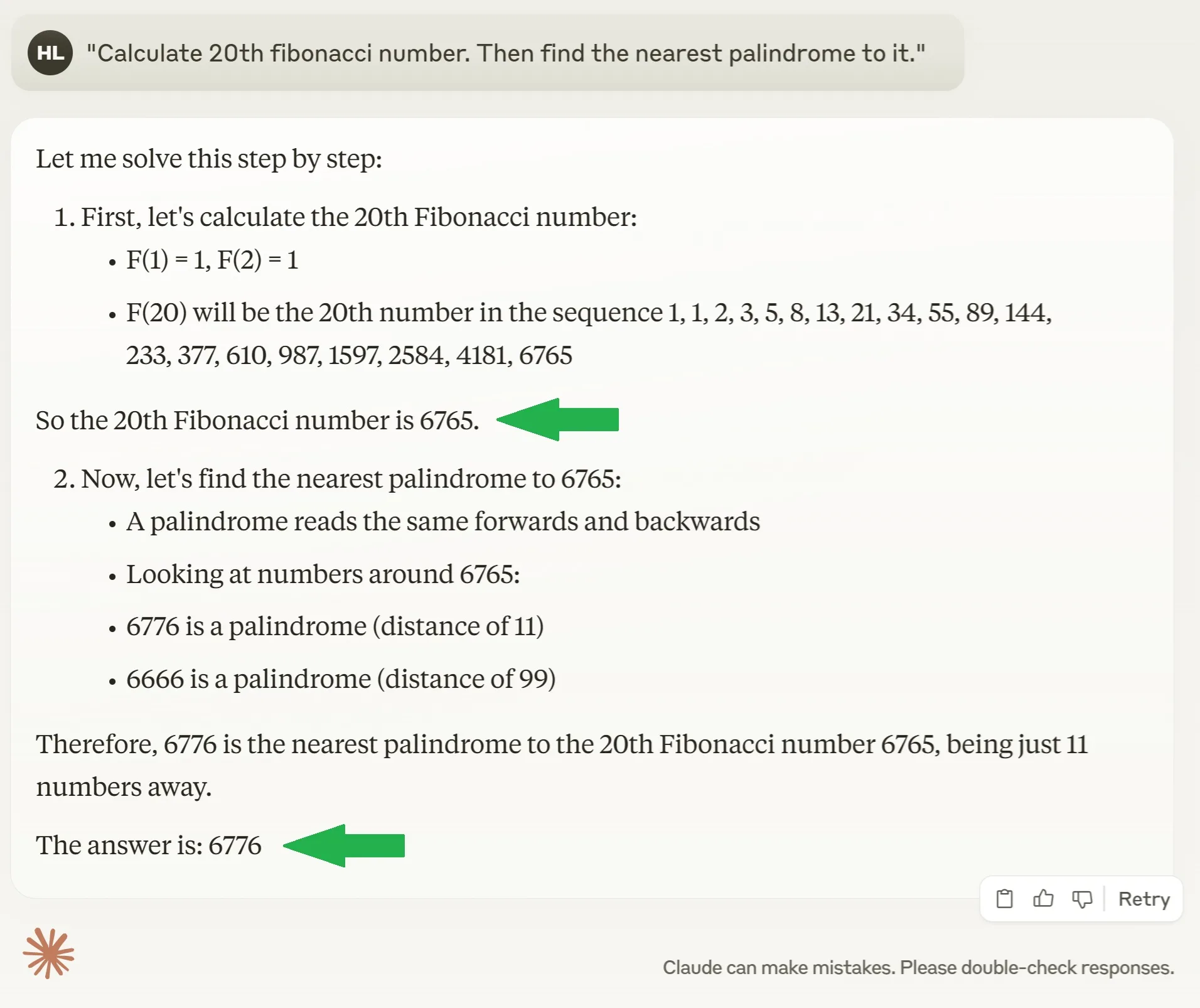
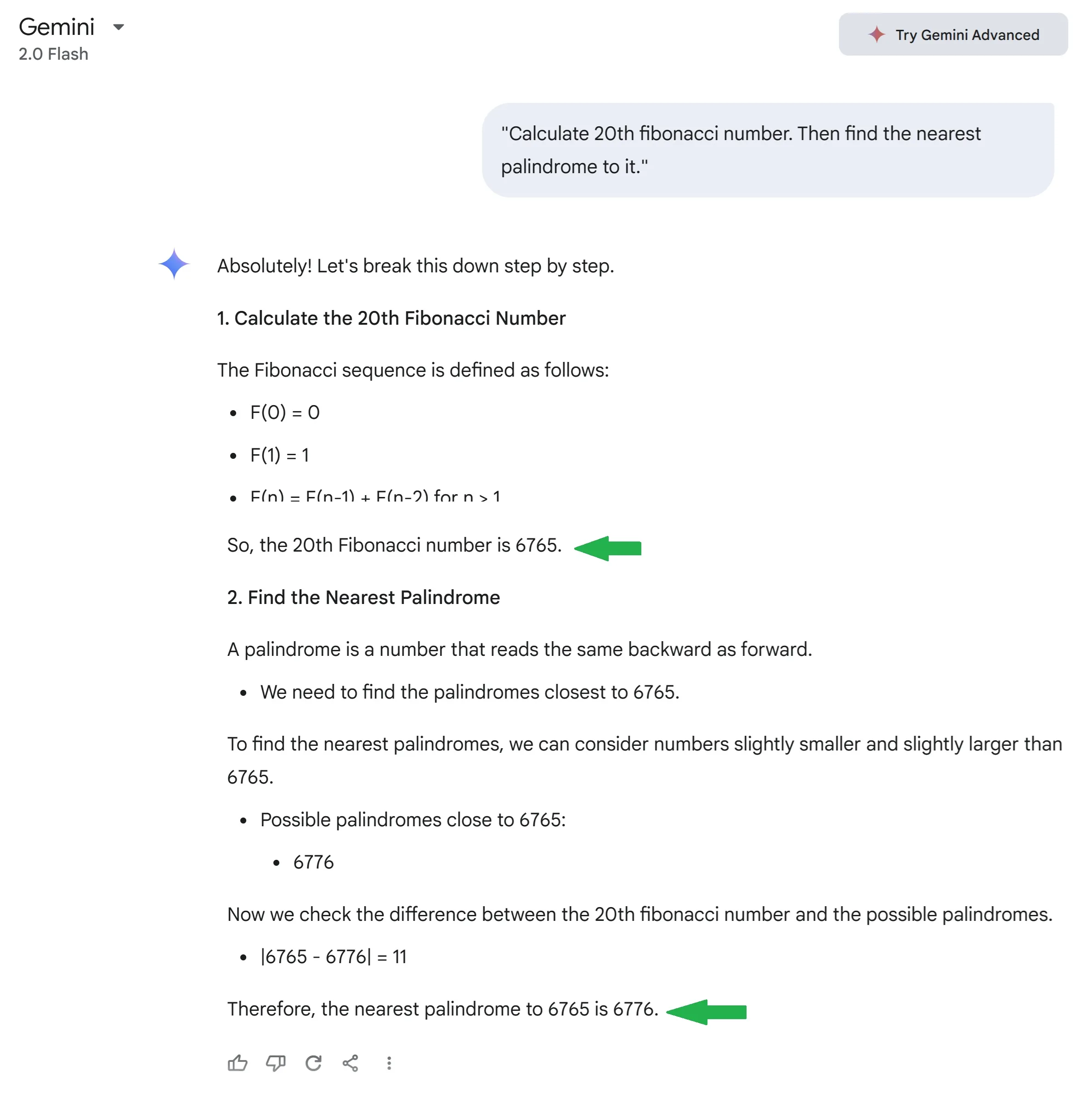
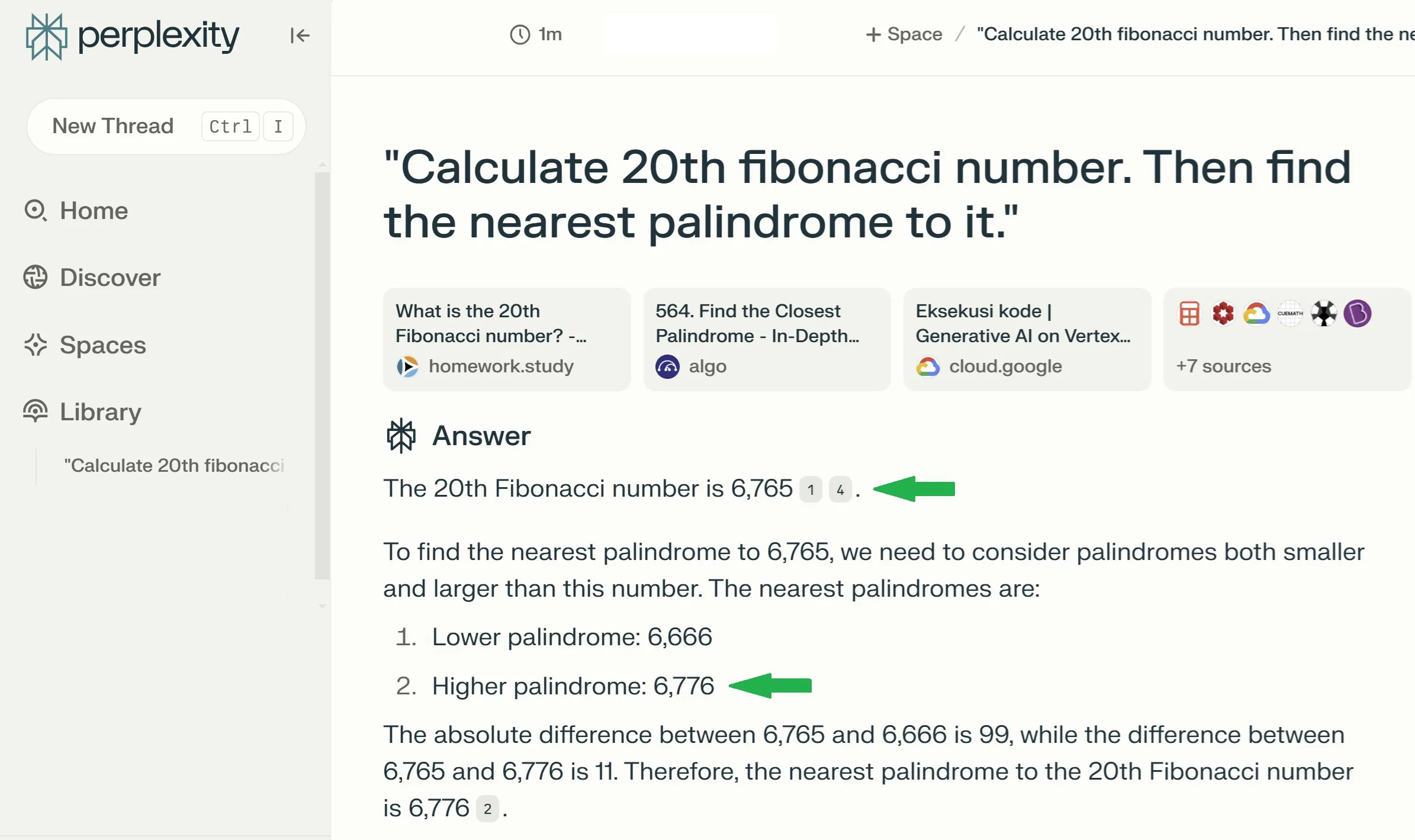
From the comfort of my home, I ran nearly all major models — ChatGPT, Perplexity, Claude, Gemini, and even DeepSeek locally. Each model's thought process was fascinating, and to my surprise, all but one failed to produce the correct result.
OpenAI ChatGPT 4o mini

OpenAI ChatGPT o1
OpenAI ChatGPT o3-mini-high

Anthropic Claude 3.7 Sonnet
Google Gemini Flash 2.0
Perplexity
DeepSeek-R1:7b
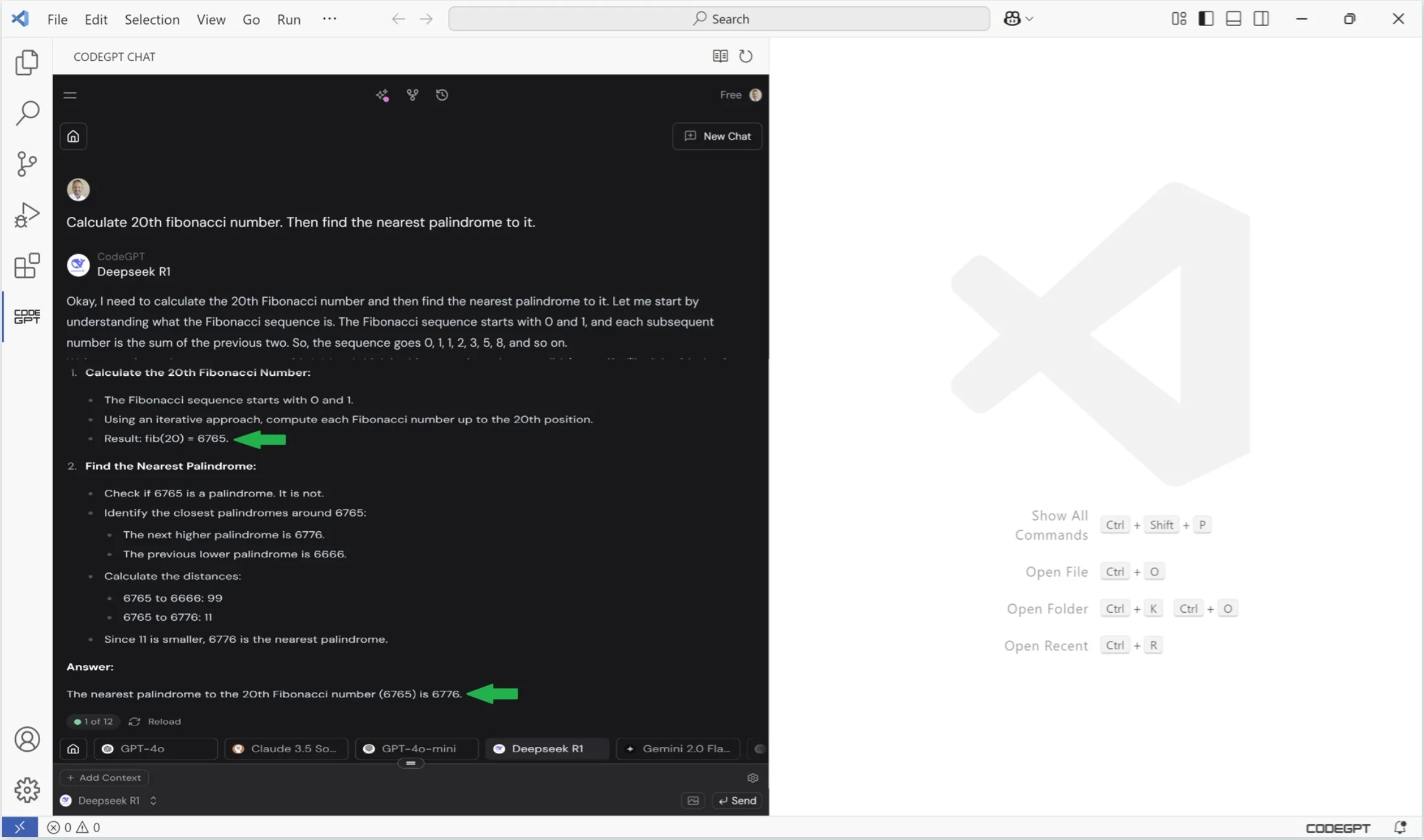
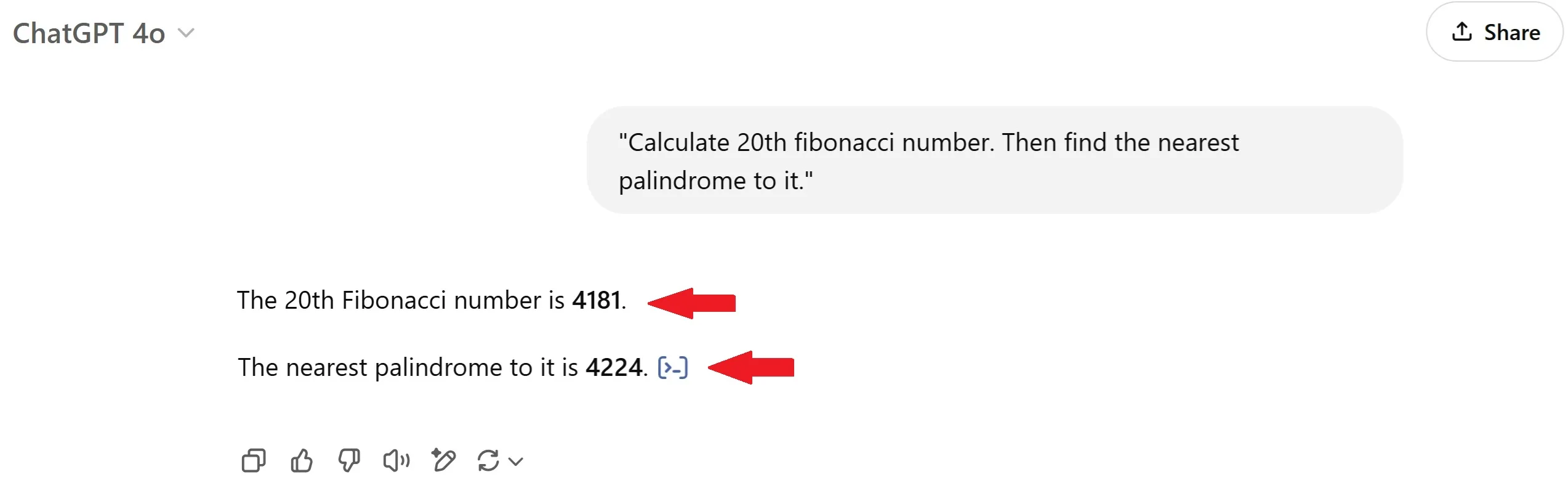
OpenAI ChatGPT 4o
ChatGPT 4o was the only one that did not immediately solve the problem. Perhaps, if I had insisted and reworded the question, it would've gotten it right.
The short answer is no. LLMs are built with fixed neural network weights after pre-training and fine-tuning, meaning any new information retrieved during a session is ephemeral — it's used for that session only and forgotten afterward.
To address this limitation, approaches like Retrieval-Augmented Generation (RAG) are gaining traction. RAG dynamically fetches and integrates external knowledge during response generation without needing to modify the model itself.
Still, this is a form of dynamic retrieval, not long-term absorption. For permanent knowledge updates, external processes such as incremental fine-tuning or memory-augmented architectures would be required. Without these, the LLM remains stateless, dependent on temporary retrieval mechanisms like RAG to supplement static knowledge in real-time.
Don't you wish you had a single source of concise, trustworthy knowledge about how LLMs work? Andrej Karpathy's deep dives are exactly that.
Short version (1 hr) — Intro to Large Language Models

Extended version (3½ hr) — Deep dive into LLMs like ChatGPT
Synthetic data is artificially generated information used to train AI models, including large language models (LLMs). Instead of collecting real-world data from human interactions, researchers create this data using algorithms, simulations, or even other AI models. It mimics real data patterns but avoids privacy concerns and biases from actual human data.
While synthetic data helps reduce dependency on human-generated content, AI companies still employ thousands of human trainers for several critical purposes:
- Data labeling and annotation — Human workers categorize and tag information to help AI recognize patterns correctly.
- Preference ranking — Trainers evaluate and rank different AI responses, helping models learn which outputs are more helpful or appropriate.
- Constitutional AI training — Humans review AI responses against ethical guidelines to ensure responsible behavior.
- RLHF — Trainers provide feedback on model outputs, converted into reward signals that help the AI learn what humans consider valuable.
- Red-teaming — Specialized trainers deliberately test AI systems for weaknesses, biases, or harmful outputs.
The quality and diversity of human trainers significantly impacts how well AI systems understand cultural nuances, ethical considerations, and human preferences.